“Architecture + discipline > model IQ alone — this is why AI stops being a pretty demo and becomes a working tool.”
Almost every AI assistant looks convincing for the first ten minutes. It phrases things well, holds the right tone, sometimes even impresses with the speed of its reasoning. But real work begins where the demo ends: when you need to remember past decisions, avoid drowning in context, return to artifacts, delegate subtasks without chaos, and tell the difference between genuine success and a decorative “seems fine.”
That’s when an uncomfortable but important truth surfaces: the weak point of most AI systems is not a lack of intelligence — it’s the absence of architecture.
This article is the first in a series about how we build Ayona/OpenClaw: an AI-native research/ops system where the model is an important — but not the only — component. Here I describe the layers that make a reliable working system and show concrete decisions tested in real production use.
Why “Ayona”? From the Greek αιώνα — flow, age, the passage of time. As an acronym: Analytical Yield Operations Nexus Agent. In Ukrainian — Аналітична Ясність Операційної Взаємодії, shortened to Ая. The name is deliberate: a system working in the flow of time must maintain continuity — and that continuity defines its architecture.
 Fig. 1. Ayona/OpenClaw Architecture: Context Layer → Execution Layer → Trust Layer with feedback loops
Fig. 1. Ayona/OpenClaw Architecture: Context Layer → Execution Layer → Trust Layer with feedback loops
Why Chatbots Aren’t Enough
The main problem with a chatbot is not that it’s “not smart enough.” The main problem is that chat is too impoverished an operational form for serious work.
In chat, everything looks linear: question, answer, clarification, another answer. But real research, engineering, or operational work is not linear. It consists of decisions, artifacts, dependencies, checks, deferred tasks, hidden assumptions, document changes, and a constant need to distinguish the relevant from the noise.
If the system has no external structure for all of this, it’s forced to simulate structure within a single dialogue. That’s a bad deal. Dialogue context is expensive, unstable, and scales poorly. It may look smooth over a short stretch, but over the long run it almost inevitably degrades: things are forgotten, things repeat, things get replaced by the heuristic “sounds plausible.”
So the question hasn’t been “which model is strongest?” for a long time. The right question is: what architecture gives the model a chance to be useful beyond a polished conversation?
What Breaks in Real AI Assistants
When we move AI from demo mode to work mode, typical failure modes quickly emerge.
Memory is either too short or too amorphous. If the assistant relies only on the current dialogue, it lives in a state of constant amnesia. But if we simply start accumulating notes, logs, and long memory dumps with no clear structure, we get the opposite problem: memory turns into noise from which it becomes increasingly hard to extract what actually matters.
Context bloats faster than its value grows. This is especially visible in systems where “just in case” logic leads to stuffing the model with as many instructions, biographical details, files, and history as possible. It seems helpful at first, but then prompt cache breaks, cost rises, and predictability falls.
Agency without boundaries. Telling an agent to “just go do it” sounds modern, but in practice it means improvisation with no control loop. Without scope, without verification, without a rollback story, such agency only increases the blast radius of mistakes.
Deceptive completion semantics. One of the nastiest failure classes: work appears complete from the outside, even though something failed or produced empty output inside. A system that can’t honestly say “it didn’t work” is unreliable regardless of how well it writes text.
This is why a mature AI assistant must be built not from the answer, but from the failure modes.
The AI-Native Working System Idea
An AI-native working system is one where the model is an important component, but not the only load-bearing pillar of the structure.
What sets it apart from an ordinary chat assistant: external cognitive and operational supports. It doesn’t try to hold everything “inside the model’s head.” It externalizes memory into managed artifacts. It describes relationships between knowledge through a graph layer. It organizes retrieval as a routing path. It delegates tasks not with bare prompts but through a bounded delegation envelope. It chooses a model not by brand prestige but by the class of work. And it accepts a simple engineering truth: without verification, rollback, and runbooks there is no reliability — only optimism.
A strong AI assistant looks less like “a smart being in a chat” and more like a cognitive-operational system with disciplined access to memory, context, tools, and actions.
Ayona/OpenClaw is moving in exactly that direction.
Real workspace structure: 00_inbox/ → 02_distill/ → 03_insights/ → 90_memory/ → 99_process/. Operational files — AGENTS.md, MEMORY.md, PLANS.md, ACTIVE_TASKS.md — form the system’s external cognitive support.
Memory as External Cognitive Support
The model should not be the only place where the history of work “lives.” First, this is technically fragile — every new session starts from zero. Second, it destroys repeatability: everything depends on the random quality of the current context.
Our design choice: a four-tier memory system where each tier is optimized for its own access pattern.
Tier 1 — Active Tasks Index. A lightweight operational registry of current tasks. Each entry contains title, aliases, status, started, last_touched, artifacts, next_step. This solves a specific problem we call semantic retrieval miss: important tasks started yesterday may not be found through a single semantic query. An explicit index guarantees that recent work won’t get lost.
Tier 2 — Daily Notes. Daily session logs in the format YYYY-MM-DD.md. Append-only, no retroactive edits.
Tier 3 — Knowledge Graph. Structured knowledge cards with typed relations (more detail in the next section).
Tier 4 — Artifact Storage. Final results, library, templates.
The key innovation is the recall cascade — a clear route for restoring context:
Active Tasks → daily notes (2–3 days) → graph cards → semantic search → file searchThe system doesn’t try to find everything with one search. It starts with the freshest and most explicit, and gradually expands the radius. This reduces dependence on any single retrieval method and ensures that current work is always front and center.
Practical effect: the assistant stops being a hostage of a single dialogue. It relies on recorded decisions, doesn’t fake continuity where there is none, yet doesn’t bloat every new prompt with the entire history of the system’s life.
 Fig. 2. Recall Cascade: from freshest & explicit to broad search across 6 steps
Fig. 2. Recall Cascade: from freshest & explicit to broad search across 6 steps
Knowledge Graph — Topology of Decisions
Even good memory quickly goes flat if it has no topology. A list of notes and files is not a knowledge structure.
Design choice: a graph layer that describes not just text but the connections between entities, projects, clusters, decisions, tasks, and deadlines.
The basic unit is a knowledge card in markdown format with YAML frontmatter:
---
id: advanced_nlp_course_syllabus
type: knowledge
clusters: [teaching, research]
status: active
primary_direction: academic_courses
tags: [education, nlp, curriculum]
related: [academic_courses, rag_pipeline_design]
deadline: 2026-04-15 # for deadline_task
---
# Advanced NLP Course Syllabus
Card content...
## Relations
- [[academic_courses|Academic Courses]]
- [[rag_pipeline_design|RAG Pipeline]]Wiki-links in the format [[card_id|Display Name]] automatically become graph edges. The generator (update_graph.py) parses all cards, collects frontmatter + wiki-links → outputs context_graph.json (nodes, edges, metadata) + a Mermaid diagram.
Cluster integrity rule: each cluster (teaching, research, academic_courses, ayona_ops) must contain ≥1 direction-link. This guarantees that no node becomes orphaned.
Node types in the visualization:
- ● Knowledge — long-term knowledge
- ◆ Deadline task — tasks with a deadline
- ■ Task — tasks without a deadline
- 💡 Insight — derived conclusions
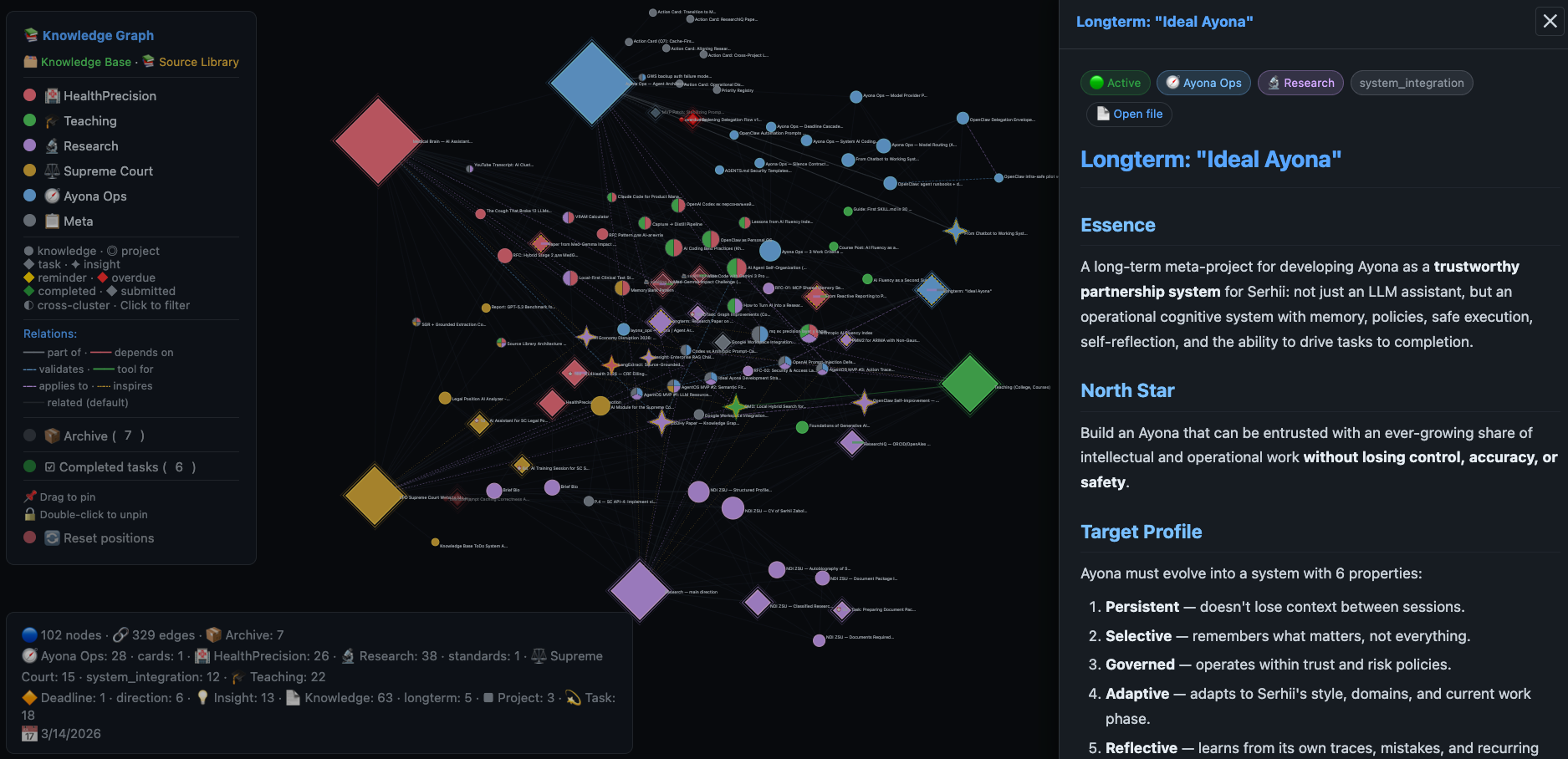
Interactive Ayona knowledge graph: 102 nodes, 329 edges, 6 clusters. The side panel shows the content of the “Ideal Ayona” card — a longterm project with roadmap, North Star, and 6 target system properties.
Practical effect: scope narrowing emerges. The assistant doesn’t need to read the entire document space. It first narrows the relevance area through the graph, then picks precise context. The knowledge graph is not decorative scaffolding. It’s a structure of decisions that reduces the entropy of knowledge access.
Retrieval as Controlled Context Access
Most systems fail not from a lack of context but from poor access to it. Either the model reads too much, too little, or the wrong thing for the moment.
Our design choice: retrieval as a controlled route, not a magic “give me what’s relevant” search.
graph layer → semantic/hybrid search → precision layer (mq) → file read (verification)Each step narrows: the graph gives scope, semantic search gives content proximity, the precision layer gives a clean entry into a large document, direct reading gives verification and targeted follow-up.
Added to this is a three-layer context filtering policy:
Layer 1 — Base (always): only stable rules — role, safety, quality. No historical details “just in case.”
Layer 2 — Operational (on topic): only active priorities (P0/P1), deadline tasks, recent decisions. Cutoff rule: if an element doesn’t influence the decision in this cycle — don’t load it.
Layer 3 — Situational (targeted): a specific file, a specific record, a specific artifact. Forbidden: generalized blocks “just in case.”
Practical effect: context stops being a mass that gets fed to the model. It becomes a managed resource. This reduces token waste, improves relevance, and makes reasoning more engineering-like.
Retrieval is not just a technique for improving recall. It’s a discipline for fighting cognitive overload in the system.
Delegation as Controlled Agency
Modern agentic systems often romanticize autonomy. But “more agency” by itself solves nothing. If the agent has no defined boundaries, access route, success criteria, and stop points, it operates not as an executor but as an improv actor in an environment with real consequences.
Two-Tier Agent Model
Instead of a monolithic super-agent, we use two tiers:
Main Orchestrator (persistent) — holds priorities, memory, deadlines, quality rules. Initiates ephemeral agents for specific projects. Aggregates results.
Ephemeral Project Agent (temporary) — created for a single project/sprint with a clear scope and Definition of Done. On completion: transfers artifacts and closes.
This prevents agent drift and context pollution — critical issues in long-running multi-turn systems.
Bounded Delegation Envelope
Delegation is formalized not as a free prompt but as a contract:
delegation_flow: v1.1
task_class: coding # design | architecture | writing | coding | research | mixed
primary_model: openai/gpt-5.4
fallback_model: anthropic/claude-sonnet-4-6
expected_output_type: artifact # text | artifact | both
expected_artifact_path: 03_insights/analysis.md
success_condition: "artifact exists and is non-empty"
failure_condition: "terminal error OR artifact missing"
verification_steps: [child_history, artifact_exists, terminal_state]
post_run_action: review_requiredEvery delegation has three possible terminal states:
- Success — no terminal error + output satisfies the success contract + artifact exists
- Failed — terminal error OR artifact missing OR verification disproves success
- Inconclusive — output is empty/ambiguous, manual review required
Key principle: inconclusive is better than false success. Empty output is not success. It is a suspicion that must be investigated.
Practical effect: agency stops being chaotic. It becomes controlled, repeatable, and auditable. One of the healthiest formulas: no naked prompts — not because prompts don’t work, but because in working systems prompts alone are not enough.
 Fig. 3. Delegation envelope v1.1: contract with three terminal states (Success / Failed / Inconclusive)
Fig. 3. Delegation envelope v1.1: contract with three terminal states (Success / Failed / Inconclusive)
Model Routing as Complexity Economics
If you simply reach for the “most powerful model” for every task, the system quickly becomes expensive, slow, and sometimes even less stable. If everything goes through the cheap tier — complex decisions suffer.
Design choice: a routing table where the model is chosen by the type of complexity, not by general prestige.
| Task type | Tier | Example |
|---|---|---|
| Architecture, creative, conceptual | Strong reasoning | Claude Opus, GPT-5.4 |
| Coding, implementation, tool-heavy | Coding-optimized | GPT-5.3 Codex, Claude Sonnet |
| Triage, formatting, summarization | Lightweight | Gemini 3 Flash, GPT-5-mini |
This is not just about budget. It’s about architectural sobriety: conceptual complexity and execution complexity are not the same, and the models for each are not necessarily identical.
Added to this is a fallback watcher — background monitoring that tracks in real time which model the provider is actually using:
if current_model ≠ primary_model → alert (debounce 30 min)If the provider quietly switches to a weaker model, the system sees it and notifies the operator. Without operational visibility, even the best routing table is useless.
Cache-Friendly Prompt Assembly as Engineering Discipline
Even a smart system degrades if its prompt assembly is built carelessly. A large unstable prefix, random context inserts, mixing static and dynamic blocks — all of this breaks prompt cache and makes behavior less predictable.
Our design choice: a three-part structure with strict prefix stability.
┌─────────────────────────────────────────┐
│ PREFIX (stable, cached) │
│ persona + rules + safety + format │
│ byte-for-byte identical across requests│
├─────────────────────────────────────────┤
│ BODY (operational context) │
│ active priorities + relevant cards │
│ minimally sufficient volume │
├─────────────────────────────────────────┤
│ TAIL (variable) │
│ current query + iteration constraints │
└─────────────────────────────────────────┘Contract requirements for PREFIX:
- Byte-for-byte stability across same-type requests
- Deterministic section order
- Normalized line endings (LF only)
- No timestamps, UUIDs, or random values
- On policy change — increment
prefix_version
Runtime quality control:
prefix_hash(request_1) == prefix_hash(request_2)must betruefor two consecutive same-type requests- If not — class C1 incident (lost cache-hit potential)
- Every request is logged:
timestamp, route, prefix_version, prefix_hash, cached_input_tokens, TTFT_ms, cost_estimate
Different providers require different approaches:
- OpenAI — auto-caching on long prefixes
- Anthropic — requires explicit
cache_controlin the request (without it — class C2 incident) - Gemini — different configuration on Vertex AI vs AI Studio
- NVIDIA NIM — KV reuse at the infrastructure level
Practical effect: prompt cache becomes not an accidental bonus but part of the architecture. Repeated run costs drop, core instruction stability is maintained. This is a good example of a general rule: in strong AI systems, efficiency often comes not from clever end-of-pipeline optimizations, but from correctly organizing the base loop at the start.
Verification, Rollback, and Runbooks as the Basis for Trust
If a system has no proof-oriented completion, it will inevitably begin substituting the appearance of a result for an actual result.
Our design choice: an explicit success contract at every level.
A concrete example — the pre-commit pipeline that runs before every git commit:
1. Graph generation (update_graph.py) — regenerate if missing
2. JSON validation (context_graph.json) — parse or block
3. Direction coverage check — every card has primary_direction
4. Relative link audit — wiki-links don't point nowhere
5. Inline docs quality gate — staged files only
6. Unit tests — only when Python files change
7. Local HTTP availability — graph accessible on localhostAny failure at any step → commit blocked. Not warnings, not “recommendations.” A hard gate.
The same approach applies to delegation: a completion message cannot be taken as the source of truth. If the output is empty, the artifact is missing, or the terminal state contradicts a polished summary — the system must say: the result is suspicious, verification required.
Another operational principle: save-as-you-go. Every significant result is saved immediately, then git committed. Mental notes don’t survive a restart. Files survive; memory doesn’t.
Practical effect: the system becomes less “magical” but significantly more reliable. The engineering of trust begins where verification, rollback, and runbooks appear.
Why This Architecture Works in Practice
This approach doesn’t try to heroically compensate for all model weaknesses with the model itself. Instead, it breaks the task into layers, each performing its own function:
- Memory maintains continuity
- The graph reduces navigation entropy
- Retrieval gives controlled access to what’s needed
- The delegation envelope constrains agency and turns it into a contract
- Model routing aligns quality with cost and task nature
- Prompt-cache discipline preserves core stability
- Verification restores the link between what the system said and what actually happened
Together this produces not “a smarter conversationalist” but a less chaotic system.
And that, perhaps, is the most important thing. In production-like knowledge/ops workflows, the primary value of AI is often not that it occasionally generates brilliant insights. The primary value is that it reduces chaos and increases repeatability without excessive loss of flexibility.
Lessons and Failure Modes
This architecture produces hard lessons.
Memory without structure does not scale. Simply accumulating summaries, logs, and notes is not enough. Without distillation and topology, they start to obstruct.
Retrieval without narrowing gives the illusion of completeness. More context does not mean better context.
Delegation without an envelope degrades into “try something.” And that is no longer reliable execution — it’s a lottery.
Completion message is not the source of truth. If the artifact is missing or the terminal state contradicts the summary, the system must say: result suspicious.
Cache economy is not a secondary optimization. If you constantly break the stable prefix with random inserts, cost and instability will grow regardless of “model quality.”
And finally, the simplest but most important: reliability does not come from good agent intentions. It comes from correctly specified boundaries, checks, and proof of execution.
From Chatbot to Operational Cognitive System
What does it take for an assistant to stop being merely a place for conversation and become a real working system?
The answer, it seems, is quite sober.
You need memory — but as external cognitive support, not the illusion of continuous consciousness. You need a knowledge graph — not for aesthetics, but as a structure of decisions and connections. You need retrieval — but as controlled access to context, not mass text-dumping into a prompt. You need delegation — but bounded, with a contract, stop points, and an expected artifact. You need model routing — as complexity economics, not a cult of one universal model. You need cache discipline — as part of system design. You need verification, rollback, and runbooks — because without them there is no operational trust.
AI system quality is determined not just by model IQ. It is determined by architecture and discipline.
The line between a chatbot and a working AI runs not along “how convincingly it speaks” but along “how reliably it is embedded in memory, context, actions, checks, and accountability.”
This is Part 1 of the Ayona/OpenClaw Architecture series. Coming up: a deep dive into the knowledge graph pipeline, cache-first prompt assembly as infrastructure, and bounded delegation in production. If this topic interests you — subscribe so you don’t miss the next installment.
Acknowledgment
Special thanks to Rinat Abdullin — author of the Schema-Guided Reasoning framework and the Telegram channel @llm_under_hood. His experiments with OpenAI Codex as a personal assistant, RFC-driven self-improvement, and the SGR approach to structured reasoning were the catalyst for many architectural decisions described in this article — from workspace structure and the memory bank pattern to the delegation envelope and the schema-guided extraction pipeline that brought us a 4th place finish at the CL4Health 2026 Workshop.
Serhii Zabolotnii — DSc, NLP/LLM Researcher, Professor, AI Systems Architect. szabolotnii.site