“Архітектура + дисципліна > model IQ alone — саме через це AI перестає бути красивим демо й стає інструментом роботи.”
Сьогодні майже кожен AI-асистент виглядає переконливо перші десять хвилин. Він добре формулює, тримає тон, іноді навіть вражає швидкістю міркування. Але реальна робота починається там, де закінчується демо: коли потрібно пам’ятати попередні рішення, не тонути в контексті, повертатися до артефактів, делегувати підзадачі без хаосу і відрізняти успіх від декоративного «ніби все гаразд».
Саме в цей момент з’ясовується неприємна, але важлива річ: слабке місце більшості AI-систем — не брак інтелекту, а відсутність архітектури.
Ця стаття — перша в серії матеріалів про те, як ми будуємо Ayona/OpenClaw: AI-native research/ops систему, де модель є важливим, але не єдиним компонентом. Тут я розповім про шари, з яких складається надійна робоча система, і покажу конкретні рішення, вироблені в реальній експлуатації.
Чому «Айона»? З грецької αιώνα — потік, вік, плин часу. Як акронім — Analytical Yield Operations Nexus Agent. Українською — Аналітична Ясність Операційної Взаємодії, скорочено Ая. Ім’я не випадкове: система, яка працює в потоці часу, має тримати тяглість — і саме це визначає її архітектуру.
 Рис. 1. Архітектура Ayona/OpenClaw: Context Layer → Execution Layer → Trust Layer з feedback loops
Рис. 1. Архітектура Ayona/OpenClaw: Context Layer → Execution Layer → Trust Layer з feedback loops
Чому чат-ботів недостатньо
Головна проблема чат-бота не в тому, що він «недостатньо розумний». Головна проблема в тому, що чат — це надто бідна операційна форма для серйозної роботи.
У чаті все виглядає лінійно: питання, відповідь, уточнення, ще одна відповідь. Але реальна дослідницька, інженерна або операційна діяльність не лінійна. Вона складається з рішень, артефактів, залежностей, перевірок, відкладених задач, прихованих припущень, змін у документах і постійної потреби відрізняти релевантне від зайвого.
Якщо система не має зовнішньої структури для всього цього, вона змушена вдавати структуру всередині одного діалогу. А це погана угода. Діалоговий контекст дорогий, нестабільний і погано масштабується. Він може виглядати гладко на короткій дистанції, але на довгій майже неминуче починає деградувати: щось забувається, щось повторюється, щось підміняється евристикою «звучить правдоподібно».
Тому питання вже давно не звучить як «яка модель найсильніша?». Коректніше інше: яка архітектура дає моделі шанс бути корисною поза межами красивої розмови?
Що ламається в реальних AI-асистентах
Коли ми переносимо AI з режиму демо в режим роботи, швидко вилазять типові failure modes.
Пам’ять або занадто коротка, або занадто аморфна. Якщо асистент покладається лише на поточний діалог, він живе в режимі постійної амнезії. Якщо ж ми просто починаємо накопичувати нотатки, логи й довгі memory dumps без чіткої структури, отримуємо протилежну проблему: пам’ять перетворюється на шум, із якого дедалі важче витягнути те, що справді важливо.
Контекст роздувається швидше, ніж зростає користь від нього. Це особливо видно в системах, де «про всяк випадок» підкладають моделі якомога більше інструкцій, біографічних даних, файлів та історії. На перших кроках це начебто допомагає, але далі руйнується prompt cache, зростає вартість, падає передбачуваність.
Агентність без меж. Коли агенту просто кажуть «піди зроби», це звучить сучасно, але практично означає імпровізацію без контрольного контуру. Без scope, без verification, без rollback story така агентність лише збільшує blast radius помилки.
Брехлива семантика завершення. Один із найнеприємніших класів збоїв: зовні робота виглядає завершеною, хоча всередині сталася помилка або порожній вихід. Система, яка не вміє чесно сказати «не вийшло», ненадійна незалежно від того, наскільки добре вона пише текст.
Саме тому дорослий AI-асистент треба будувати не від відповіді, а від failure modes.
Ідея AI-native working system
AI-native working system — це система, де модель є важливим компонентом, але не єдина опора конструкції.
Її відмінність від звичайного чат-асистента: зовнішні когнітивні й операційні опори. Вона не намагається тримати все «в голові моделі». Вона виносить пам’ять у керовані артефакти. Описує зв’язки між знаннями через graph layer. Організовує retrieval як маршрут доступу. Делегує задачі не голим промптом, а через bounded delegation envelope. Обирає модель не за престижем бренду, а за класом роботи. І визнає просту інженерну істину: без verification, rollback і runbooks немає надійності, є лише оптимізм.
Сильний AI-асистент більше схожий не на «розумну істоту в чаті», а на когнітивно-операційну систему з дисциплінованим доступом до пам’яті, контексту, інструментів і дій.
Ayona/OpenClaw рухається саме в цей бік.
Реальна структура робочого простору: 00_inbox/ → 02_distill/ → 03_insights/ → 90_memory/ → 99_process/. Операційні файли — AGENTS.md, MEMORY.md, PLANS.md, ACTIVE_TASKS.md — формують зовнішню когнітивну опору системи.
Пам’ять як зовнішня когнітивна опора
Модель не повинна бути єдиним місцем, де «живе» історія роботи. По-перше, це технічно крихко — кожна нова сесія починається з нуля. По-друге, це руйнує повторюваність: усе тримається на випадковій якості поточного контексту.
Наш дизайн-вибір: чотирирівнева система пам’яті, де кожен рівень оптимізований під свій тип доступу.
Рівень 1 — Active Tasks Index. Легкий операційний реєстр поточних задач. Кожен запис містить title, aliases, status, started, last_touched, artifacts, next_step. Це вирішує конкретну проблему, яку ми називаємо semantic retrieval miss: важливі задачі, розпочаті вчора, можуть не знайтися через один семантичний запит. Explicit index гарантує, що свіжа робота не загубиться.
Рівень 2 — Daily notes. Щоденні логи сесій у форматі YYYY-MM-DD.md. Append-only, без редагування заднім числом.
Рівень 3 — Knowledge Graph. Структуровані картки знань із типізованими зв’язками (детальніше — в наступній секції).
Рівень 4 — Artifact storage. Фінальні результати, бібліотека, шаблони.
Ключова інновація — recall cascade, чіткий маршрут відновлення контексту:
Active Tasks → daily notes (2–3 дні) → graph cards → semantic search → file searchСистема не намагається знайти все одним пошуком. Вона починає з найсвіжішого і найбільш explicit, і поступово розширює радіус. Це зменшує залежність від одного retrieval-методу і гарантує, що поточна робота завжди на першому плані.
Практичний ефект: асистент перестає бути заручником одного діалогу. Він опирається на зафіксовані рішення, не вдає безперервність там, де її немає, і водночас не роздуває кожен новий prompt історією всього життя системи.
 Рис. 2. Recall Cascade: від найсвіжішого й explicit до широкого пошуку через 6 кроків
Рис. 2. Recall Cascade: від найсвіжішого й explicit до широкого пошуку через 6 кроків
Knowledge graph — топологія рішень
Навіть добра пам’ять швидко стає пласкою, якщо вона не має топології. Список нотаток і файлів — це ще не структура знань.
Дизайн-вибір: graph layer, який описує не просто тексти, а зв’язки між сутностями, проєктами, кластерами, рішеннями, задачами й дедлайнами.
Базова одиниця — knowledge card у форматі markdown із YAML-frontmatter:
---
id: advanced_nlp_course_syllabus
type: knowledge
clusters: [teaching, research]
status: active
primary_direction: academic_courses
tags: [education, nlp, curriculum]
related: [academic_courses, rag_pipeline_design]
deadline: 2026-04-15 # для deadline_task
---
# Advanced NLP Course Syllabus
Зміст картки...
## Зв'язки
- [[academic_courses|Academic Courses]]
- [[rag_pipeline_design|RAG Pipeline]]Wiki-links у форматі [[card_id|Display Name]] автоматично стають ребрами графа. Генератор (update_graph.py) парсить усі картки, збирає frontmatter + wiki-links → виводить context_graph.json (nodes, edges, metadata) + Mermaid-діаграму.
Cluster integrity rule: кожен кластер (teaching, research, academic_courses, ayona_ops) має містити ≥1 direction-зв’язок. Це гарантує, що жоден вузол не стане orphaned.
Типи вузлів у візуалізації:
- ● Knowledge — довгострокові знання
- ◆ Deadline task — задачі з дедлайном
- ■ Task — задачі без дедлайну
- 💡 Insight — вироблені висновки
Результат доступний як інтерактивний D3.js-граф із фільтрацією за кластерами, пошуком, toggle archived/completed і preview markdown-вмісту прямо у вузлі.
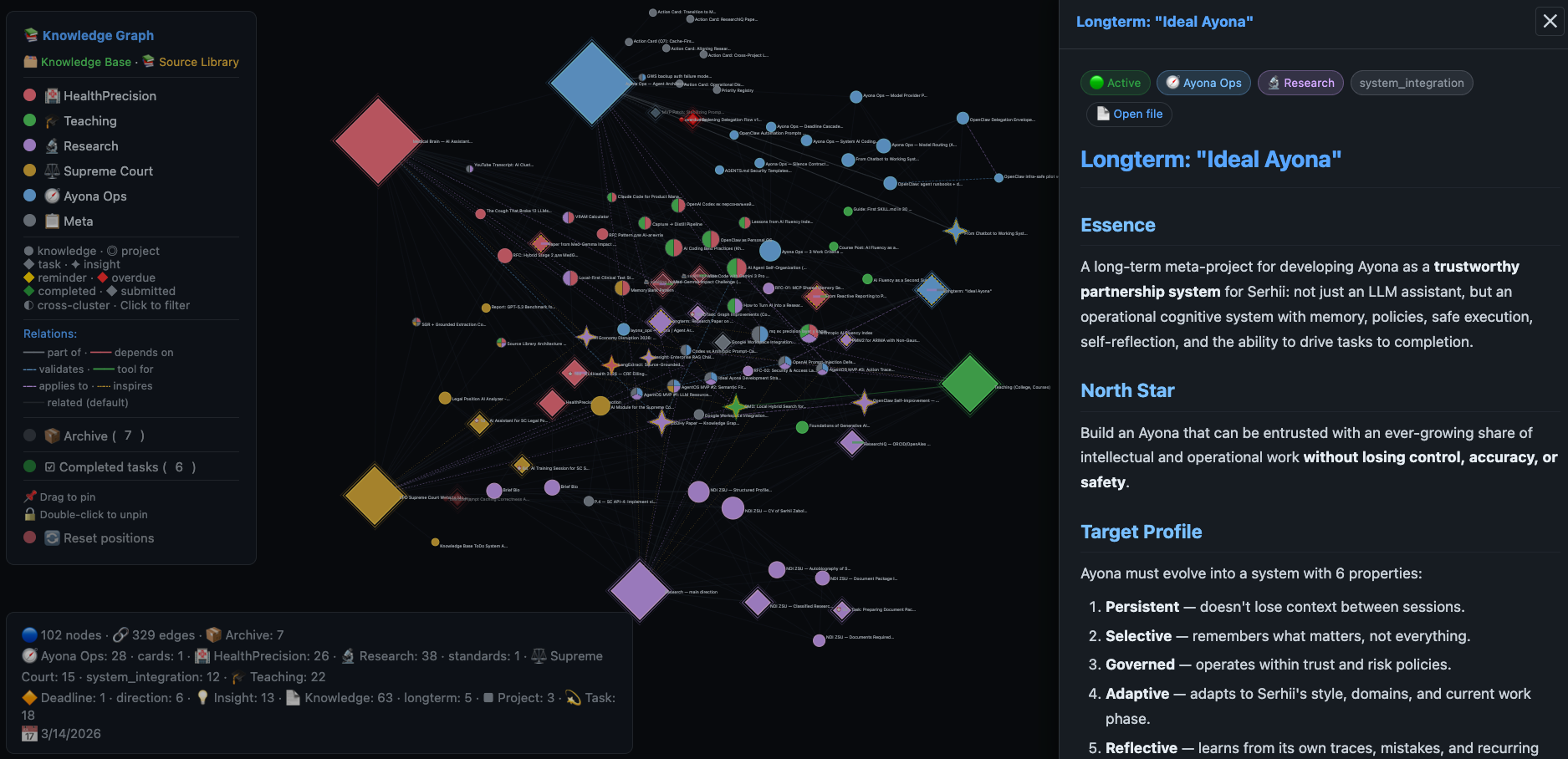
Інтерактивний knowledge graph Ayona: 102 вузли, 329 зв’язків, 6 кластерів. Бічна панель показує вміст картки «Ideal Ayona» — longterm-проєкт з roadmap, North Star і 6 цільовими властивостями системи.
Практичний ефект: з’являється scope narrowing. Асистент не мусить читати весь простір документів. Він спершу звужує область релевантності через граф, а вже потім добирає точковий контекст. Knowledge graph — не декоративна надбудова. Це структура рішень, яка зменшує ентропію доступу до знань.
Retrieval як керований доступ до контексту
Більшість систем програє не через брак контексту, а через поганий доступ до нього. Або модель читає забагато, або замало, або не те, що треба саме зараз.
Наш дизайн-вибір: retrieval як керований маршрут, а не магічний пошук «дай релевантне».
graph layer → semantic/hybrid search → precision layer (mq) → file read (verification)Кожен крок звужує: граф дає scope, semantic search — змістову близькість, precision layer — акуратний вхід у великий документ, пряме читання — verification і точкове дочитування.
До цього додається three-layer context filtering policy:
Layer 1 — Base (завжди): тільки стабільні правила — роль, безпека, якість. Ніяких історичних деталей «про всяк випадок».
Layer 2 — Operational (по темі): лише активні пріоритети (P0/P1), задачі з дедлайнами, свіжі рішення. Правило відсікання: якщо елемент не впливає на рішення в цьому циклі — не завантажувати.
Layer 3 — Situational (точково): конкретний файл, конкретний запис, конкретний артефакт. Заборонено: генералізовані блоки «just in case».
Практичний ефект: контекст перестає бути суцільною масою, яку згодовують моделі. Він стає керованим ресурсом. Це зменшує token waste, покращує релевантність і робить reasoning більш інженерним.
Retrieval — це не просто техніка підвищення recall. Це дисципліна боротьби з когнітивним перевантаженням системи.
Delegation як контрольована агентність
Сучасні агентні системи часто романтизують автономію. Але «більше агентності» саме по собі нічого не вирішує. Якщо агенту не задано межі, маршрут доступу, критерії успіху і точки зупинки, він працює не як виконавець, а як improv actor у середовищі з реальними наслідками.
Двотіерна модель агентів
Замість монолітного супер-агента ми використовуємо два тіери:
Main Orchestrator (постійний) — тримає пріоритети, пам’ять, дедлайни, якісні правила. Ініціює ephemeral-агентів для конкретних проєктів. Агрегує результати.
Ephemeral Project Agent (тимчасовий) — створюється для одного проєкту/спринту з чітким scope і Definition of Done. Після завершення: передає артефакти і закривається.
Це запобігає agent drift і context pollution — критичним проблемам у довготривалих multi-turn системах.
Bounded delegation envelope
Делегування оформлюється не як вільний prompt, а як контракт:
delegation_flow: v1.1
task_class: coding # design | architecture | writing | coding | research | mixed
primary_model: openai/gpt-5.4
fallback_model: anthropic/claude-sonnet-4-6
expected_output_type: artifact # text | artifact | both
expected_artifact_path: 03_insights/analysis.md
success_condition: "artifact exists and is non-empty"
failure_condition: "terminal error OR artifact missing"
verification_steps: [child_history, artifact_exists, terminal_state]
post_run_action: review_requiredКожне делегування має три можливі terminal states:
- Success — немає terminal error + output задовольняє success contract + artifact існує
- Failed — terminal error АБО artifact missing АБО verification disproves success
- Inconclusive — output порожній/неоднозначний, потрібна ручна перевірка
Ключовий принцип: inconclusive краще за false success. Порожній output не є успіхом. Це — підозра, яку треба перевірити.
Практичний ефект: агентність перестає бути хаотичною. Вона стає контрольованою, відтворюваною й аудитабельною. Одна з найздоровіших формул: no naked prompts — не тому, що prompts не працюють, а тому, що в робочих системах одних prompts недостатньо.
 Рис. 3. Delegation envelope v1.1: контракт із трьома terminal states (Success / Failed / Inconclusive)
Рис. 3. Delegation envelope v1.1: контракт із трьома terminal states (Success / Failed / Inconclusive)
Model routing як економіка складності
Якщо для будь-якої задачі просто брати «найсильнішу модель», система швидко стає дорогою, повільною й інколи навіть менш стабільною. Якщо все пускати через дешевий tier — страждають складні рішення.
Дизайн-вибір: routing table, де модель обирається за типом складності, а не за загальним престижем.
| Тип задачі | Тіер | Приклад |
|---|---|---|
| Architecture, creative, conceptual | Strong reasoning | Claude Opus, GPT-5.4 |
| Coding, implementation, tool-heavy | Coding-optimized | GPT-5.3 Codex, Claude Sonnet |
| Triage, formatting, summarization | Lightweight | Gemini 3 Flash, GPT-5-mini |
Це не лише про бюджет. Це про архітектурну тверезість: концептуальна складність і execution complexity — не те саме, і моделі для них не обов’язково ті самі.
До цього додається fallback watcher — фоновий моніторинг, який у реальному часі відстежує, яку модель фактично використовує провайдер:
if current_model ≠ primary_model → alert (debounce 30 min)Якщо провайдер тихо перемикає на слабшу модель, система це бачить і повідомляє оператора. Без operational visibility навіть найкращий routing table марний.
Cache-friendly prompt assembly як інженерна дисципліна
Навіть розумна система деградує, якщо її prompt assembly побудований недисципліновано. Великий нестабільний префікс, випадкові вставки контексту, змішування статичних і динамічних блоків — усе це руйнує prompt cache і робить поведінку менш передбачуваною.
Наш дизайн-вибір: трьохчастинна структура з жорсткою стабільністю префікса.
┌─────────────────────────────────────────┐
│ PREFIX (stable, cached) │
│ persona + rules + safety + format │
│ byte-for-byte identical між запитами │
├─────────────────────────────────────────┤
│ BODY (operational context) │
│ active priorities + relevant cards │
│ minimally sufficient volume │
├─────────────────────────────────────────┤
│ TAIL (variable) │
│ current query + iteration constraints │
└─────────────────────────────────────────┘Контрактні вимоги до PREFIX:
- Byte-for-byte стабільність між однотипними запитами
- Детерміністичний порядок секцій
- Нормалізація line endings (тільки LF)
- Жодних timestamps, UUIDs або випадкових значень
- При зміні policy — інкремент
prefix_version
Runtime quality control:
prefix_hash(request_1) == prefix_hash(request_2)має бутиtrueдля двох послідовних однотипних запитів- Якщо ні — інцидент класу C1 (втрата cache-hit potential)
- Кожен запит логується:
timestamp, route, prefix_version, prefix_hash, cached_input_tokens, TTFT_ms, cost_estimate
Різні провайдери вимагають різних підходів:
- OpenAI — автокешування на довгих префіксах
- Anthropic — потрібен explicit
cache_controlв запиті (без нього — інцидент класу C2) - Gemini — різна конфігурація на Vertex AI vs AI Studio
- NVIDIA NIM — KV reuse на рівні інфраструктури
Практичний ефект: prompt cache стає не випадковим бонусом, а частиною архітектури. Знижується вартість повторних запусків, зберігається стабільність ядра інструкцій. Це хороший приклад загального правила: у сильних AI-системах ефективність часто народжується не з хитрих оптимізацій наприкінці, а з правильної організації базового контуру на початку.
Verification, rollback і runbooks як умова довіри
Якщо система не має proof-oriented завершення, вона неминуче починає підміняти результат видимістю результату.
Наш дизайн-вибір: explicit success contract на кожному рівні.
Конкретний приклад — pre-commit pipeline, який запускається перед кожним git commit:
1. Graph generation (update_graph.py) — regenerate if missing
2. JSON validation (context_graph.json) — parse or block
3. Direction coverage check — кожна картка має primary_direction
4. Relative link audit — wiki-links не ведуть у нікуди
5. Inline docs quality gate — staged files only
6. Unit tests — лише при зміні Python-файлів
7. Local HTTP availability — граф доступний по localhostБудь-який fail на будь-якому кроці → commit blocked. Не warnings, не «рекомендації». Hard gate.
Такий самий підхід діє в delegation: completion message не можна вважати джерелом істини. Якщо output порожній, артефакт відсутній або terminal state суперечить красивому summary — система повинна сказати: результат підозрілий, потрібна перевірка.
Ще один операційний принцип: save-as-you-go. Кожен значущий результат зберігається негайно, потім git commit. Ментальних нотаток не існує після перезапуску. Files survive; memory doesn’t.
Практичний ефект: система стає менш «магічною», але значно надійнішою. Інженерія довіри починається там, де з’являються verification, rollback і runbooks.
Чому така архітектура працює на практиці
Цей підхід не намагається героїчно компенсувати всі недоліки моделі самою моделлю. Замість цього він розкладає задачу на шари, кожен з яких виконує власну функцію:
- Пам’ять тримає тяглість
- Граф зменшує ентропію навігації
- Retrieval дає керований доступ до потрібного
- Delegation envelope обмежує агентність і перетворює її на контракт
- Model routing узгоджує якість із ціною і природою задачі
- Prompt-cache discipline зберігає стабільність ядра
- Verification відновлює зв’язок між тим, що система сказала, і тим, що реально сталося
У сумі це дає не «розумнішого співрозмовника», а менш хаотичну систему.
І це, можливо, найважливіше. У production-подібних knowledge/ops workflows головна цінність AI часто не в тому, що він іноді генерує блискучі інсайти. Головна цінність — у тому, що він зменшує хаос і збільшує повторюваність без надмірної втрати гнучкості.
Уроки й failure modes
З такої архітектури випливають жорсткі уроки.
Пам’ять без структури не масштабується. Просто накопичувати summary, логи й записи недостатньо. Без distillation і topology вони починають заважати.
Retrieval без narrowing дає ілюзію повноти. Більше контексту не означає кращий контекст.
Делегування без envelope деградує в «спробуй щось зробити». А це вже не reliable execution, а лотерея.
Completion message — не джерело істини. Якщо артефакт відсутній або terminal state суперечить summary, система має сказати: результат підозрілий.
Cache economy — не другорядна оптимізація. Якщо постійно ламати stable prefix випадковими вставками, ціна й нестабільність зростатимуть незалежно від «якості моделі».
І нарешті, найпростіше, але найважливіше: надійність не виникає з хороших намірів агента. Вона виникає з правильно заданих меж, перевірок і доказів виконання.
Від чат-бота до operational cognitive system
Що потрібно, щоб асистент перестав бути просто місцем для розмови і став реальною робочою системою?
Відповідь, здається, доволі твереза.
Потрібна пам’ять — але як зовнішня когнітивна опора, а не ілюзія безперервної свідомості. Потрібен knowledge graph — не для краси, а як структура рішень і зв’язків. Потрібен retrieval — але як керований доступ до контексту, а не масове закидання тексту в prompt. Потрібне делегування — але bounded, з контрактом, stop points і expected artifact. Потрібен model routing — як економіка складності, а не культ однієї універсальної моделі. Потрібна cache discipline — як частина системного дизайну. Потрібні verification, rollback і runbooks — бо без них немає operational trust.
Якість AI-системи визначається не лише model IQ. Вона визначається архітектурою і дисципліною.
Межа між чат-ботом і робочим AI проходить не по лінії «наскільки переконливо він говорить», а по лінії «наскільки надійно він вбудований у пам’ять, контекст, дії, перевірки й відповідальність».
Це перша частина серії про архітектуру Ayona/OpenClaw. У наступних матеріалах: детальний розбір knowledge graph pipeline, cache-first prompt assembly як інфраструктура, і bounded delegation в production. Якщо ця тема цікава — підписуйтесь, щоб не пропустити продовження.
Подяка
Окрема подяка Рінату Абдуліну — автору концепції Schema-Guided Reasoning і телеграм-каналу @llm_under_hood. Саме його експерименти з OpenAI Codex як персональним асистентом, RFC-driven self-improvement і підхід SGR для структурованого міркування стали каталізатором багатьох архітектурних рішень, описаних у цій статті — від структури робочого простору й memory bank pattern до delegation envelope і schema-guided extraction pipeline, який приніс 4-те призове місце на CL4Health 2026 Workshop.
Сергій Заболотній — NLP/LLM дослідник, викладач, архітектор AI-систем. szabolotnii.site